



The HTML Document
Every HTML document you create or load is derived from this basic format:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>
You can think of it as a template. And, following this template will help ensure that the page is displayed as the developer (you) intended. It not only says what should be displayed, but also includes relevant information that tells the browser how to display it. This template can be broken down into 3 parts:
- DOCTYPE: Describes the type of HTML. While there are technically different types, for 99.999% of the HTML you'll write, you’ll likely be fine with <!DOCTYPE html>. The declaration helps the browser determine what type of HTML document it’s trying to parse and display.
- : Describes meta information about the site, such as the title, and provides links to scripts and stylesheets the site needs to render and behave correctly. It is never visible.
- : Describes the actual content of the site that users will see. It will contain the content that will be displayed on the page. It is always visible.
HTML Doctypes
An HTML document will usually start with a type declaration (which is not a tag, so it should not have a closing tag). The declaration helps the browser determine what type of HTML document it’s trying to parse and display. Browsers look for this doctype declaration to determine which rendering mode to use to render the site. Generally, newer sites follow standard HTML specifications. The current standard HTML specification is called HTML5 The tag, which tells the browser that everything enclosed inside the ... should be parsed as HTML. Then you have the two main sections of your HTML document: and
The ,but the information in it describes the page and links to other files the browser needs to render the website correctly. For instance, the is responsible for:
the document’s title (the text that shows up in browser tabs): About Me.
- associated CSS files (for style): .
- associated JavaScript files (multipurpose scripts to change rendering and behavior): .
- the charset being used (the text's encoding): . It will allow your website to display any Unicode character.
- keywords, authors, and descriptions (often useful for SEO): .
Hyperlinks
The power of the web is that pages can lead to other pages. When you click on a link on a web page, it takes you to another page. This link is called a hyperlink. Hyperlinks are created with anchor elements, which generally look like:
<a href="https://www.google.com">Google</a>
Inside the opening a tag there is href, which stands for "reference." This is called an attribute.Attributes like href describe the properties of HTML elements. In this case, the href attribute is the target URL that the link will open. The content inside the anchor element is the text that users see displayed on the page.
Image
An image is made with an img element. It looks like so:
<img src="http://somewebsite.com/image.jpg" alt="short description">
The source attribute, src, is like the href of a link - it is the URL of the image you want to display.The alt attribute stands for "alternative description," which is important for people who use screen readers to browse the web. This is text that will show up in lieu of the actual image. Images do not need closing tags! (For the eager, these are called "void elements".)
Paths
A path is a way of describing where a file is stored. There are essentially two domains for paths that you'll need to consider as a web developer: paths to find files on your computer, local files, and paths to find files on other computers, external files.
Local Paths
Computers have folders (also called "directories"). Operating systems like Windows, Mac and Linux organize all of your files into a tree of directories called a file system. There's a top-most directory, often called the root, that contains all of the other directories. Within the root, there are files and directories. Within those directories are more files and more directories. And within those directories are even more files and directories, and so on.
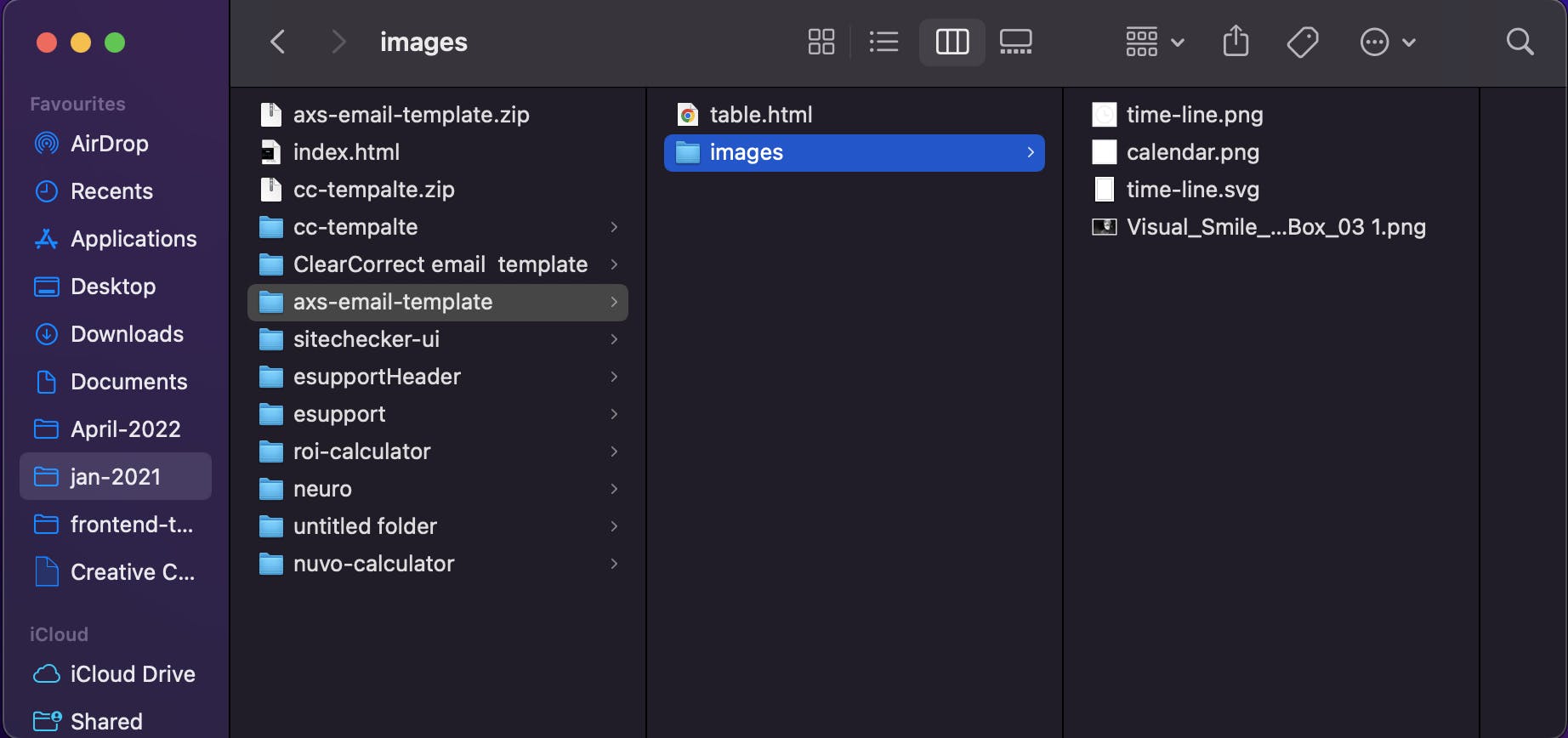
Every file has an address, which we call the "path." An absolute path is written in relation to the computer's root directory. For instance, a file in the Documents folder on a Mac has a path that looks like this:
/Users/divyanshi/Documents/jan-2021/axs-email-template/images/time-line.png
time-line.png is stored inside Documents/. Users/, divyanshi/ , Documents/ are all names of directories. Documents/ lives inside divyanshi/ and divyanshi/ lives inside Users/. Users/ is inside the root directory, which is represented by the first /. The rest of the / are used to separate directories.
When you open an any file in your browser, you're seeing the absolute path to the file on your computer.

red line in the screenshot above indicates file:// is called the protocol and absolute path to the time-line.png This URL will only work for you on your computer. As no one else has your file system, this URL is unique to your computer. If you want other people to be able to access it, then you need an...
External Paths
The process of loading a website from a URL like google.com mimics opening an HTML file that you've written and saved to your computer. Every website starts with an HTML file. It just so happens that when you want to visit a website, the HTML file that you want to open lives on a different computer. The computer responsible for giving you a website's files is called a server. Pointing your browser to google.com sends a request to Google's server for the HTML file (and others) that your computer needs to load the Google website. You can think of google.com as the root path of Google's server (computer) that anyone can access (the reality of the situation is actually much more complicated but the general idea is true). Unlike your personal computer (for now!), Google's servers run software that expose files to the web, which means that they make them available to anyone who wants them. Servers have an external path that anyone can access and is the reason why the web works. Different websites are just different collections of files. Every website is really just a server (or many servers) with an external address, which we call a URL. Servers store files and send them to computers who request them (the requesting computers are called clients). There are different protocols for serving files, the most common of which on the web are HTTP and HTTPS. When you open a file on your own computer, you're using the file protocol.
Relative Paths
The relative path is similar to the absolute path, but it describes how to find a path to a file from a directory that is not the root directory. A relative path takes advantage of the location of one file to describe where another file can be found. Relative paths work the same for both local and external paths. Let's break down two examples of absolute paths to see how relative paths work. External:
<a href="http://labs.udacity.com/fend/example/hello-world.html">Hello, world!</a>
Local:
<a href="/Users/cameron/Udacity/etc/labs/fend/example/hello-world.html"> Hello, world!</a>
href is really just a path to a file.